Our argument
What is predictive optimization?
We coin the term predictive optimization to refer to automated decision-making systems where machine learning is used to make predictions about some future outcome pertaining to individuals, and those predictions are used to make decisions about them.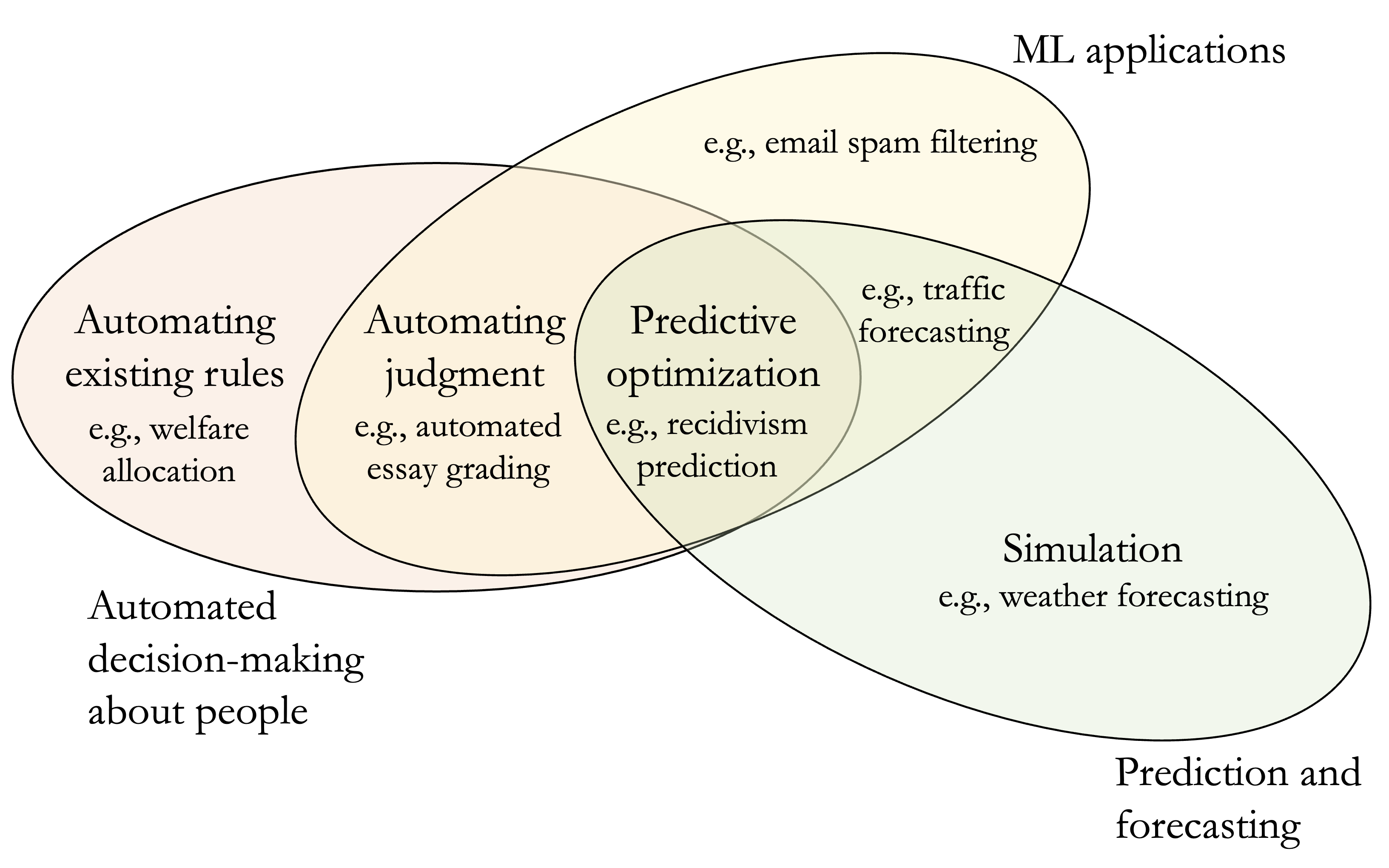
We review 387 reports, articles, and web pages from academia, industry, non-profits, governments, and modeling contests, and find many examples of predictive optimization. Concretely, we compile 47 that we could conceive of as predictive optimization, and present them in this spreadsheet. We narrow these down to eight particularly impactful examples to evaluate the potential risks of deploying predictive optimization.
Case studies
| Application | Developer | What is being predicted (construct) | Proxy for the prediction (target) | Decision made based on prediction |
|---|---|---|---|---|
| COMPAS | Northpointe/ Equivant | Pretrial risk | Re-arrest in two years or failure to appear in court | Whether to release a defendant pre-trial or what bail amount to set |
| Allegheny Family Screening Tool | Allegheny County | Child maltreatment | Placement into foster care or multiple referrals within two years | Whether to investigate a family for child maltreatment |
| Hirevue hiring platform | Hirevue | Job performance | Job success after joining a firm | Whether to hire someone or invite them to the next round of interviews |
| Navigate | EAB | School dropout | Varies by school, e.g., "enrollment until next fall," "graduation within four years," or "graduation at any point of time" | Whether to offer targeted interventions to aid students |
| Upstart | Upstart | Creditworthiness | Repayment or future salary | Whether to offer a loan to someone and at what rates |
| Facebook Suicide Prediction | Facebook (Meta) | Suicide risk | Whether someone was assessed to be at high risk of suicide | Whether to refer someone for a welfare check |
| ImpactPro | Optum | Medical risk | Healthcare costs | Whether to put a patient in the high-risk health program |
| Velogica | SCOR | Life insurance risk | Mortality or policy lapse | Whether to offer a life insurance policy and at what rates |
What developers claim
The developers of these systems make a number of claims, with three common ones being: high accuracy in predicting the outcome, fairness across demographic groups, and efficiency gains by reducing the time spent by human decision-makers (thereby reducing costs).
For instance, Hirevue's front page displays "Fast. Fair. Flexible. Finally, hiring technology that works how you want it to." Upstart claims that "future versions of the model will continue to be fair," "Upstart's model is significantly more accurate than traditional lending models," and that 73% of their loans are fully automated. These claims are used as selling points for attracting customers; for example, Optum has a document called a "sell sheet" where they list attributes such as "cost, risk and quality."



Flaws of predictive optimization
We present seven flaws of predictive optimization. Our aim is to outline a set of objections inherent to predictive optimization that cannot be easily fixed using a design or engineering change. Taken together, these critical flaws undermine the legitimacy of applications of predictive optimization.
Automated decision-making algorithms are used to make decisions based on the data they are trained on. The type of decision can affect how well the algorithms work. Even if a tool makes the correct prediction, if the decision taken based on this decision is flawed, the tool cannot work as claimed. A decision taken using automated tools is also called an intervention. Additionally, decisions based on predictions might themselves affect the outcomes being predicted. For example, a higher bail amount—based on predicted recidivism—can increase the likelihood of recidivism (Gupta et al. 2016).
In constructing an application of predictive optimization, some existing data must be chosen for the model to predict. For example, to predict who will do well in college, the application could try to predict the GPA at the end of the 1st year of college. The outcome being predicted is called the target variable. The target variable is typically chosen to roughly correspond to the decision maker’s goal—also called the construct. Obermeyer et al. 2019 find that Optum ImpactPro has a construct of healthcare needs and a target variable of healthcare costs. However, due to reasons such as unequal access to healthcare, the costs are often a poor proxy for the actual healthcare needs.
When the distribution of data on which an ML model is trained is not representative of the distribution on which it will be deployed, model performance suffers. The Public Safety Assessment (PSA) tool uses a population of 1.5 million cases from 300 U.S. jurisdictions. However, in some of the jurisdictions in which it is used, the base rate of violent recidivism is lower than the base rate in the tool's training data by more than a factor of 10. This results in risk thresholds for pre-trial detention that are severely miscalibrated, resulting in over-detention (Corey 2019).
Limits to prediction
One of the characteristics of predictive optimization is that the prediction target is a future event in an individual’s life. Thus, there are many inherent limits to prediction that limit how accurate the system could be. Epic, one of the largest healthcare tech companies in the U.S., released a plug-and-play sepsis prediction tool in 2017. When the tool was released, the company claimed that it had an AUC between 0.76 and 0.83. Over the next five years, the tool was deployed across hundreds of U.S. hospitals. But a 2021 study found that the tool performed much worse: it had an AUC of 0.63 (Wong et al. 2021). Following this study and a series of news reports, Epic stopped selling its one-size-fits-all sepsis prediction tool (Ross 2022).
Disparate performance
Disparate performance refers to differences in performance for different demographic groups. However, a system that is fair in a statistical sense may nonetheless perpetuate, reify, or even amplify long-standing cycles of inequality. Oregon state recalled a tool they built for deciding which families should be investigated by social workers (The Associated Press 2022) after public critiques about the racial bias of a similar tool, AFST, were published (Ho and Burke 2022).
When decision-making algorithms are deployed in consequential settings, they must include mechanisms for contesting such decisions. In 2013, the Netherlands deployed a predictive algorithm to detect welfare fraud. The algorithm wrongly accused 30,000 parents of welfare fraud, and led to debts of hundreds of thousands of Euros. In many cases, the decisions were based on incorrect data, but the decision subjects had no recourse. In the fallout over the algorithm’s use, the Prime Minister and his entire cabinet resigned (Heikkilä 2022).
A canonical example of Goodhart’s law is the cobra effect: when the colonial British government offered bounties for dead cobras to reduce the cobra population, the response instead was people breeding more cobras to kill. Similarly, predictive optimization can create unintended incentives for decision subjects to game the system. The LYFT score (Life Years from Transplant) was proposed for allocating kidneys to patients in need of a transplant based on a prediction about how long they would live after the transplant (Robinson 2022). Using this score would result in a disincentive for patients with kidney issues to take care of their kidney function: if their kidneys failed at a younger age, they would be more likely to get a transplant.
Analysis summary
Below, we present a table that demonstrates how our seven flaws apply to each of our eight consequential applications.
A full-circle (![]() ) represents concrete evidence that an application suffers from a flaw, and a half-filled circle (
) represents concrete evidence that an application suffers from a flaw, and a half-filled circle (![]() ) represents partial or circumstantial evidence. This is often due to lack of transparency from the tool's developers or lack of research into that specific application.
) represents partial or circumstantial evidence. This is often due to lack of transparency from the tool's developers or lack of research into that specific application.
The density of this matrix supports our claim that these flaws are widespread in deployments of predictive optimization.
Click on the circles below to read a brief summary of our critique.
| Prediction | Case Study | Intervention vs prediction | Target-construct mismatch | Distribution shifts | Limits to prediction | Disparate performance | Lack of contestability | Goodhart's law |
|---|---|---|---|---|---|---|---|---|
| Pre-trial risk | COMPAS |
|
|
|
|
|
|
|
| Child maltreatment | ASFT |
|
|
|
|
|
|
|
| Job performance | HireVue |
|
|
|
|
|
|
|
| School dropout | EAB Navigate |
|
|
|
|
|
|
|
| Creditworthiness | Upstart |
|
|
|
|
|
|
|
| Suicide |
|
|
|
|
|
|
|
|
| Medical risk | Optum ImpactPro |
|
|
|
|
|
|
|
| Life insurance risk | Velogica |
|
|
|
|
|
|
|
Rubric for assessing legitimacy
We provide a rubric for those trying to resist predictive optimization as well as those trying to deploy it.Through the rubric, we aim to aid civil liberties advocates, community organizers, and activists in challenging predictive optimization when deployed in their communities. When a new application is deployed, they can use the rubric to challenge developers' claims of accuracy, efficiency, and fairness that are often used to justify and legitimize the application. The rubric can also aid researchers and journalists when investigating predictive optimization by providing a concrete set of failure modes to look for in a tool.
Since the flaws are so widespread, we want to shift the burden of justifying why the tools are not harmful onto developers and decision-makers.
Acknowledgments
We are grateful to Emily Cantrell, Amrit Daswaney, Jakob Mökander, Matthew J. Salganik, and Paul Waller for their valuable feedback on drafts of this paper. We thank the participants of the Philosophy, AI, and Society workshop for their inputs. We also thank our colleagues at the Center for Information Technology Policy who provided valuable feedback during research seminars.Citing this paper
To cite this work, please use this BibTeX entry.Authors
| Name | Affiliation | |
|---|---|---|
| Angelina Wang* | Princeton University | angelina.wang@princeton.edu |
| Sayash Kapoor* | Princeton University | sayashk@princeton.edu |
| Solon Barocas | Microsoft Research; Cornell University | solon@microsoft.com |
| Arvind Narayanan | Princeton University | arvindn@cs.princeton.edu |